import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import numpy as np
import matplotlib.pyplot as pltMultilayer Perceptron (MLP)
Here, the basis of Neural Networks will be presented, focusing on Multilayer Perceptrons (MLPs).
Theory
Deep Learning (DL) is a subarea of Machine Learning (ML) that is based on models composed of Neural Networks (NNs) (LeCun, Bengio, and Hinton 2015). Here, the basis of NNs will be presented, focusing on Multilayer Perceptrons (MLPs).
NNs were inspired by biological neural networks (Prince 2023). The smallest part of a NN is a neuron, which was famously modeled as a perceptron. A perceptron is a function of the form: \[ \hat{y} = \sigma\left(b + \sum_{i=1}^n w_ix_i\right), \tag{1}\] where \(x_i\) are the inputs, \(w_i\) are the input coefficients, \(b\) is the bias, \(\sigma : \mathbb R \to \mathbb R\) is the activation function and \(\hat{y}\) is the output. Here, the variables \(w_i\) and \(b\) are referred as learnable parameters of the model.Therefore, the perceptron receives \(n\) input signals and calculates their affine combination, then passes this value as input to a non-linear function. This can be visualized in Fig. 1.
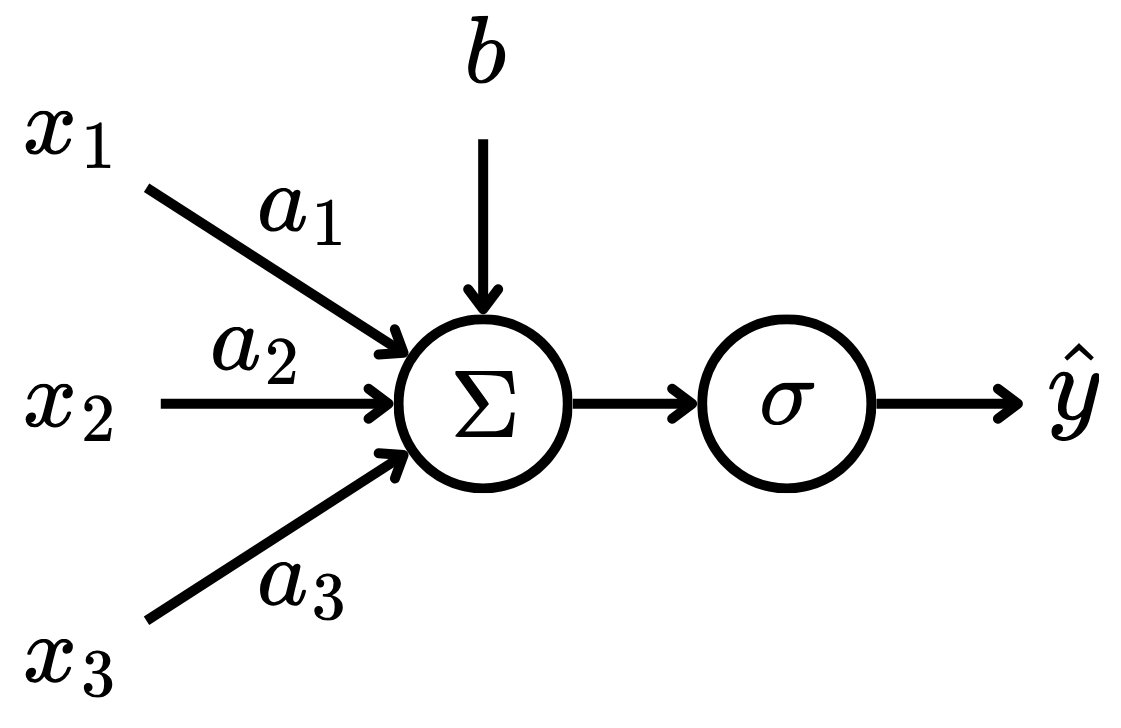
To make perceptrons more complex models, one can stack multiple perceptrons in layers, creating a Multilayer Perceptron (MLP). That is, a layer of a MLP is of the form: \[ \hat{\boldsymbol{y}} = \sigma\left(\boldsymbol{Wx} + \boldsymbol{b}\right), \tag{2}\] where \(\boldsymbol{x} \in \mathbb R^n\) is the input vector, \(\boldsymbol{W} \in \mathbb R^{m\times n}\) is the linear coefficient matrix, \(\boldsymbol{b} \in \mathbb R^m\) is the bias vector and \(\boldsymbol{\hat{y}} \in \mathbb R^m\) is the output vector. Here, the hyperparameter \(m\) is the number of neurons – or perceptrons – in the given layer. The rows of the learnable parameters \(\boldsymbol{W}\) and \(\boldsymbol{b}\) play the same role as in Eq. 1, that is: \[ \begin{bmatrix} \hat{y}_1 \\ \hat{y}_2 \\ \vdots \\ \hat{y}_m \end{bmatrix} = \sigma \left( \begin{bmatrix} w_{11} & w_{12} & \cdots & w_{1n} \\ w_{21} & w_{22} & \cdots & w_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ w_{m1} & w_{m2} & \cdots & w_{mn} \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{bmatrix} + \begin{bmatrix} b_1 \\ b_2 \\ \vdots \\ b_m \end{bmatrix} \right). \tag{3}\] Note that the activation function \(\sigma : \mathbb R^m \to \mathbb R^m\) is now applied element-wise in the \(\boldsymbol{Wx} + \boldsymbol{b}\) vector.
In MLPs, layers of perceptrons are grouped sequentially in order to approximate a mapping from the input space \(\mathcal X\) to the output space \(\mathcal Y\), with the intermediate layers of the model being called hidden layers. That is, given a dataset \(\mathcal D = \{\boldsymbol x_i, \boldsymbol y_i\}_{i=1}^N\) with \(N\) observations, the input vector \(\boldsymbol x_i \in \mathcal X\) is processed by the MLP layers until the final layer, which should yield a vector \(\boldsymbol{\hat{y}}_i \approx \boldsymbol y_i \in \mathcal Y\). Fig. 2 depicts the diagram of a MLP.
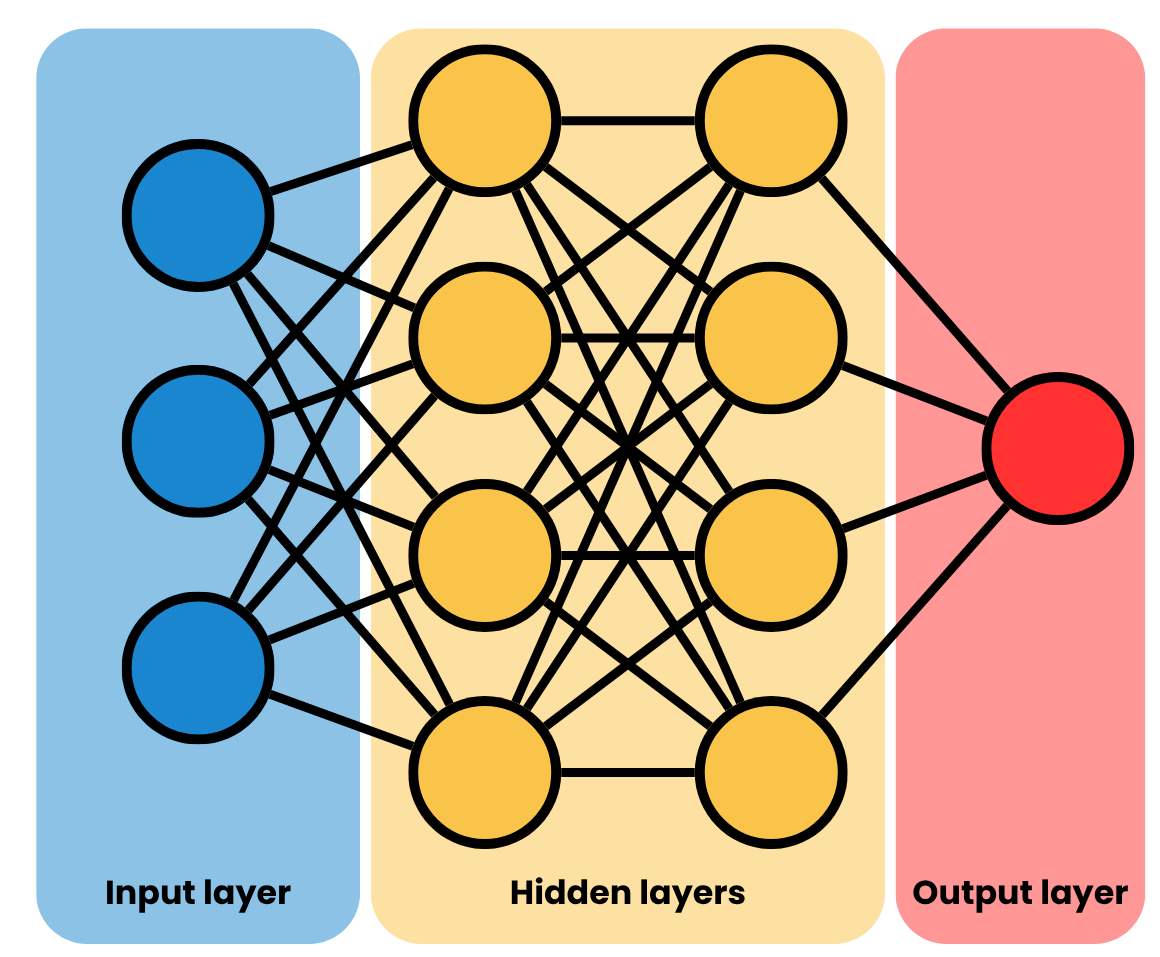
As any other ML model, the MLP has some hyperparameters, which need to be carefully tuned. The most notable ones are:
- Number of hidden layers;
- Number of neurons per hidden layer;
- Activation function.
To train a MLP, one needs a dataset \(\mathcal D = \{\boldsymbol x_i, \boldsymbol y_i\}_{i=1}^N\) of observations – this approach is called Supervised Learning. With that, given a loss function \(\mathcal L : \mathcal Y^2 \to \mathbb R\) that measures how close the prediction \(\boldsymbol{\hat{y}}_i\) is to the observation \(\boldsymbol y\), one updates the learnable parameters of the model – the \(\boldsymbol W\) and \(\boldsymbol b\) from Eq. 2 using backpropagation. This is an algorithm of the form: \[ \boldsymbol \Theta^{(i + 1)} = \boldsymbol \Theta^{(i)} - \eta \nabla_{\boldsymbol \Theta^{(i)}} \mathcal L. \tag{4}\] That is, in a sequence of iterations, the learnable parameters of the model in the \(i\)-iteration \(\boldsymbol \Theta^{(i)}\) are updated using the the gradient of the loss function with respect to the learnable parameters of the MLP \(\eta \nabla_{\boldsymbol \Theta^{(i)}} \mathcal L\), considering a step size of \(\eta \in \mathbb R^+\).
Code
Here, a simple MLP will be trained in a classification task using the MNIST dataset – which contains images of hand-written digits. Importing the libraries.
Setting the device.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")Using device: cudaNormalizing and creating the dataloaders.
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
transforms.Lambda(lambda x: torch.flatten(x))
])
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('./data', train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)Creating and instantiating the MLP. A model with one hidden layer containing 128 neurons and ReLU activations will be used.
class MLP(nn.Module):
def __init__(
self,
input_size=784,
hidden_size=128,
output_size=10
):
super(MLP, self).__init__()
self.classifier = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, output_size)
)
def forward(self, x):
return self.classifier(x)
def fit(
self,
device,
train_loader,
optimizer,
criterion,
epochs
):
self.train()
self.train_loss = []
for epoch in range(1, epochs + 1):
epoch_loss = 0.0
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = self(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(train_loader)
self.train_loss.append(avg_loss)
print(f"Epoch [{epoch}/{epochs}] | Average Loss: {avg_loss:.6f}")
model = MLP().to(device)
params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Number of params: {params}")Number of params: 118282Making the training loop.
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
model.fit(device, train_loader, optimizer, criterion, epochs=10)Epoch [1/10] | Average Loss: 0.825505
Epoch [2/10] | Average Loss: 0.316130
Epoch [3/10] | Average Loss: 0.261313
Epoch [4/10] | Average Loss: 0.223332
Epoch [5/10] | Average Loss: 0.193474
Epoch [6/10] | Average Loss: 0.170477
Epoch [7/10] | Average Loss: 0.152012
Epoch [8/10] | Average Loss: 0.136417
Epoch [9/10] | Average Loss: 0.123799
Epoch [10/10] | Average Loss: 0.112818Plotting the training curve.
plt.plot(model.train_loss)
plt.xlabel("Epoch")
plt.ylabel("Cross-Entropy Loss")
plt.show()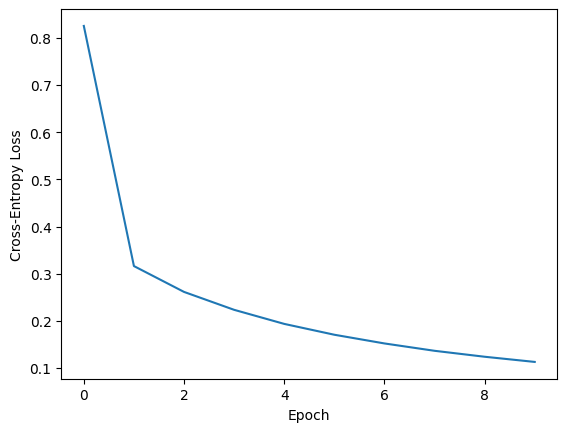
Calculating the metrics.
model.eval()
all_preds = []
all_targets = []
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
preds = output.argmax(dim=1)
all_preds.extend(preds.cpu().numpy())
all_targets.extend(target.cpu().numpy())
print(classification_report(all_targets, all_preds, digits=4)) precision recall f1-score support
0 0.9660 0.9867 0.9763 980
1 0.9756 0.9850 0.9803 1135
2 0.9691 0.9738 0.9715 1032
3 0.9542 0.9703 0.9622 1010
4 0.9595 0.9654 0.9624 982
5 0.9638 0.9552 0.9595 892
6 0.9629 0.9749 0.9689 958
7 0.9666 0.9582 0.9624 1028
8 0.9755 0.9384 0.9566 974
9 0.9617 0.9445 0.9530 1009
accuracy 0.9656 10000
macro avg 0.9655 0.9652 0.9653 10000
weighted avg 0.9656 0.9656 0.9655 10000
Plotting the confusion matrix.
cm = confusion_matrix(all_targets, all_preds)
plt.figure(figsize=(7, 7))
sns.heatmap(
cm,
annot=True,
fmt='d',
cmap='Blues',
cbar=False,
xticklabels=range(10),
yticklabels=range(10)
)
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.show()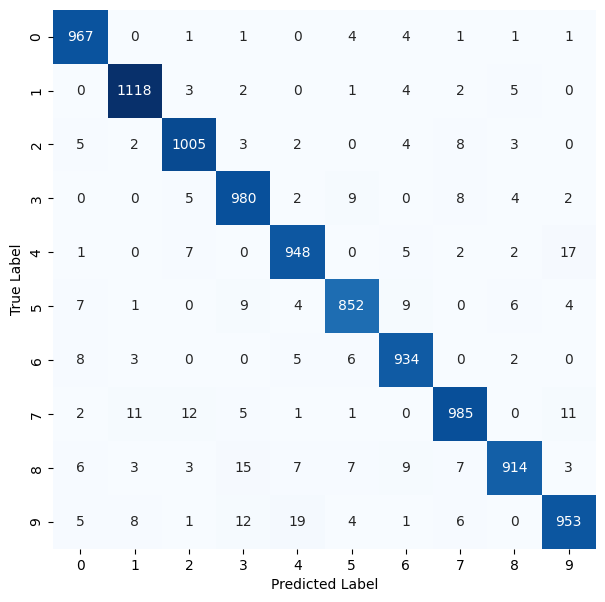
References
LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep Learning. Nature. Vol. 521. 7553. Nature Publishing Group UK London.
Prince, Simon JD. 2023. Understanding Deep Learning. MIT press.